

The #1 way to get better AI outputs.
How to build a light eval structure for your AI projects.

Ever wondered how your outputs get worse the more you adjust your prompt? Why every time you fix one failure, you end up introducing two more?
Most builders assume this means the prompt needs more work. It doesn’t.
What’s missing is a way to know whether an output is actually good before it reaches you. Evals give you that signal. Here’s how to build one in under an hour.
Today’s edition is brought to you by Wispr Flow.

Wispr Flow makes writing quick and clear with seamless voice dictation. It is the fastest, smartest way to type with your voice. Our entire team is obsessed with it since they launched. Try Wisprflow Pro for 3 months absolutely free by signing up using the link below.
But first, what are evals? (And why you need them)
One thing about LLMs — they don’t retrieve answers like Google does. They predict the most likely next word until the response appears complete. Meaning, they can be confidently wrong.
An external check solves this. The moment you show your LLM what a good output is, how to get to it, and what it looks like through an eval, the LLM runs the output against the standard every time. So you can see where things are breaking and tweak your AI to get a better response.
Today’s problem statement.
We recently built a scraper to help us source topics for newsletters. It did the job. It filtered topics from the right sources, ensured they were recent, and displayed a list in the format we’d specified.
But it didn’t tell us which topics would make good newsletters. Here’s what that output looked like.
[Fintech] PhonePe crossed 50 million registered merchants covering 98% of India’s pin codes — payments infrastructure is won; financial services now 11.55% of revenue, up from under 1% in FY23.
🏷 Revenue size ✅ (Entrackr FY25: ₹7,115 Cr) | New category entry ✅ (Outlook Business: financial services diversification)
2. [Fintech] Acko appointed Morgan Stanley, ICICI Securities, and Kotak for IPO at $2–2.5 Bn — losses down 37% in FY25, EBITDA margin improving from -31% to -14%, the digital-first insurance model has found its footing.
🏷 Revenue size ✅ (Entrackr FY25: ₹2,837 Cr) | Incumbents (LIC, traditional insurers) haven’t cracked digital-first ✅ (Inc42 FY25 analysis)
3. [Fintech] Oolka raised $14 Mn Series A led by Accel, backed personally by Meesho co-founders — AI credit management for 6 million users with $2.5 Mn ARR; early but the category has real structural demand.
(No brand tag — ₹100 Cr revenue threshold not met. Included on editorial quality: new model in an underformalised category.)
4. [Healthtech] Superhealth and Even bet on smaller single-specialty hospitals to change care economics — fixed-salary doctors, standardised surgical pricing, ₹70–75 lakh per bed vs industry’s ₹2–3 Cr.
(No brand tag — revenue not at ₹100 Cr threshold yet for either company. Included on editorial quality: category formalisation story, incumbents like Apollo haven’t cracked the cost model at this price point.)
Today, we’ll build an eval for this — so the scraper doesn’t just find topics, it finds the right ones.
Wait, what is a good newsletter topic?
For GrowthX, a good topic is one that makes readers stop and evaluate a business critically. We basically had to teach an AI something that came intuitively to us.
We started by defining what “good” actually means.
After a lot of whiteboarding and looking at newsletters that did well for us, we realised good isn’t a single thing — it has levels. A topic about a no-name brand in the news from a month ago sits at the bottom. A big consumer brand with an upcoming IPO and a broader market implication sits at the top. So we built a scoring rubric around that. L1 is the weakest, L5 is the strongest — across four parameters.
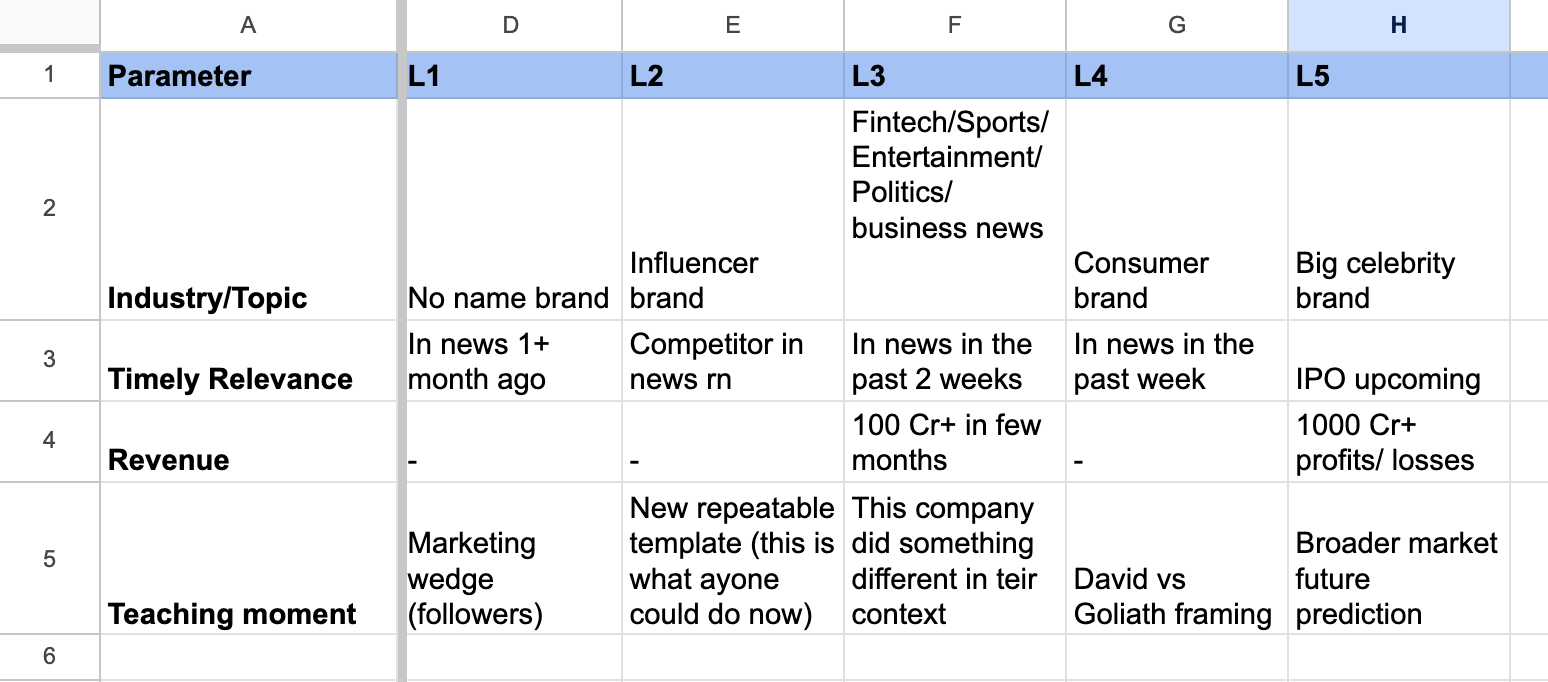
Plus, not every parameter is as important for making our business newsletter. For instance, a teaching moment matters more than revenue, time and industry/topic. After all, you want to take away something after reading a newsletter. Revenue matters more than timeliness because a big number means real stakes — you’re learning from a business that has already proven something at scale, not just one that happened to be in the news this week. So on, and so forth.
This is why we added weights to each parameter.

With this framing, the AI gives each topic a numerical score. Here’s what that looks like after a run (we’re showing you two topics that scored differently based on a rubric we just created).
2. Funding — SoftBank booking ₹2,873 Cr on Lenskart straight into a 46% revenue quarter is the oldest VC move in the book: exit into your winner’s peak right after lock-in expiry, before the market reprices the next leg of risk.
Industry L4(4) + Timely L5(10) + Revenue L5(15) + Teaching L5(20) = 49/50
—
5. Governance & Policy — CCPA fined PhysicsWallah ₹5 lakh for dark patterns. Small fine. Big signal. Every Indian growth team's fake-urgency timer is now on legal notice. Industry L3(3) + Timely L4(8) + Revenue skipped + Teaching L5(20) = 31/35
Why a rubric alone isn’t enough.
See the SoftBank story above?
It almost ran in the newsletter. The problem? SoftBank is not a business builder. It’s an investor booking profit, not a business lesson a founder would like. The rubric had no way to catch this because the rubric only scores what’s there — it doesn’t check what’s missing.
Having a hard filter (code-based grader) helps here.
Before the rubric runs, every story passes through a set of binary checks. Just pass or fail.
In this case, a hard filter asks this: Is there a single named company at the centre of the story? Is it in a sector we cover? Did it happen this week? Is the primary actor a founder or operator — not an investor doing a transaction? If any check fails, the story drops.
The SoftBank story fails here — the primary actor is an investor, the transaction is purely financial, and there is no operating company strategy angle. Drop and done.
What happens if the eval still breaks?
Look closely at the PhysicsWallah article that passed.
5. Governance & Policy — CCPA fined PhysicsWallah ₹5 lakh for dark patterns. Small fine. Big signal. Every Indian growth team’s fake-urgency timer is now on legal notice. Industry L3(3) + Timely L4(8) + Revenue skipped + Teaching L5(20) = 31/35
Our AI model gave it a high score despite it not having a clear business learning. Why? The model used the rubric, which only said ‘broader market future prediction’ — and a single fine got inflated into a structural India signal. Vague language was producing a wrong answer.
Enter the calibration loop (human grader)
We updated the rubric. L5 now requires: a new law, regulation, or market structure shift. A single enforcement action does not qualify unless it creates a legal precedent that changes how all companies in the sector must operate.
After the update, the same story re-scored: L2.
Here’s what a good topic looks like now.
1. Media/Entertainment — Kuku: ₹240 Cr to ₹1,400 Cr in one year. AI cuts content cost. IPO filed. Microdrama is India’s next content category — AI built the moat, not the marketing budget. 🏷 🚩
Industry L4(4) + Timely L5(10) + Revenue L5(15) + Teaching L5(20) = 49/50
2. Sports Business — Zee got FIFA cheap. JioStar blinked at $15M. Zee locked 39 tournaments through 2034. In Indian media rights, patience beats a bigger cheque. 🚩
Industry L3(3) + Timely L5(10) + Revenue skipped + Teaching L5(20) = 33/35
This is just the tip of the iceberg.
We covered three graders here. A hard filter, a scoring rubric, and a calibration loop. That is a working eval for a newsletter topic scraper — built inside a Claude project, no code, no infrastructure. It is also the simplest version of what evals can do.
The same logic applies to customer support agents, research tools, coding assistants, onboarding flows or any system where you need to know whether the output is actually good before it reaches a user.
There are also eval types we haven’t covered, such as regression suites, capability benchmarks, and multi-trial consistency checks. Each solves a different failure mode.
We’ll walk through a few more in upcoming editions. Stick around for the ride.